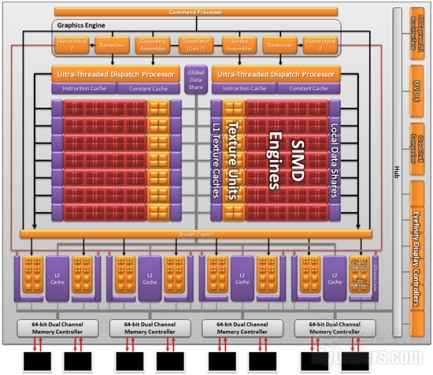
 The Radeon HD 6900 series was finally released, but with a new architecture, the actual performance is not as good as many people think. Is it true that the new architecture is not so forceful? Actually speaking, this is a true transition. AMD used this as a guinea pig and is making new preparations for the future.
The Radeon HD 6900 series was finally released, but with a new architecture, the actual performance is not as good as many people think. Is it true that the new architecture is not so forceful? Actually speaking, this is a true transition. AMD used this as a guinea pig and is making new preparations for the future. To understand why AMD uses VLIW4 4D stream processor architecture design, we must first understand why AMD uses VLIW5 5D stream processor architecture design, and to answer the question later, we must go back to the more distant DX9 era, the seeds back in that It has been buried.
VLIW: Very long instruction word, refers to an architecture that is designed to take advantage of instruction-level parallelism (ILP). A non-superscalar processor that executes instructions in order cannot fully utilize the processor's resources, potentially resulting in low performance.
I think that coloring is still new, and pixel and vertex shaders are still independent. Previous ATI chose the VILW5 design for their vertex shader, because ATI concluded from its own data that this is the best configuration of the vertex shader block, which can simultaneously process a four-component dot product (such as w, x , y, z) and a scalar component (such as lighting).
In 2007, ATI released the Radeon HD 2000 series of the R600 architecture, which was the first to introduce a unified coloring architecture in the PC world, and once again used VLIW5. Although this is a DX10 product, DX9 vertex shading is still handled well. Before GPGPU general-purpose computing became popular, this architecture was well-adapted.
Then enter 2008. Graphic card manufacturers generally have to consider the circumstances of two years or even longer when planning products, so the design of Cayman Radeon HD 6900 series has already begun. At the time, GPGPU general-purpose computing was just starting. The market that NVIDIA started to chase was worth up to several million dollars. DX10 games have not yet formed, but AMD predicts that general computing will become very important two years later (that is, now). DX9 will also basically give way to DX10/11, so we must re-evaluate the pros and cons of VLIW5 design in advance.
Sure enough, GPGPU general computing has already begun to popularize, Windows 7 and DX10/11 are also pushing DX9 to the stage of history. According to AMD's internal data, the average of the five processing slots in the VLIW5 architecture can only be used in 3.4, that is, there will be a waste of one half of the game. Obviously, the very ideal VLIW5 design in DX9 is outdated. It is too wide. The stream processor unit (SPU) must be shortened and the layout of the stream processor (SP) inside must be redesigned.
AMD's graphics core architecture relies heavily on instruction-level parallel operations (ILPs), which put instructions in a single thread and have nothing to do with other parallelizable threads. The ideal situation under VLIW5 is that five instructions can be scheduled and executed on each SPU every clock cycle, but this probability is very low. It is reasonable to say that the average of 3.4 uses, but the conversion is still less than 80%, the result is very difficult to extract ILP from the workload, resulting in the best, the worst application environment is too different.
In stark contrast to this is thread-level parallel computing (TLP), where threads that do not have any association can execute at the same time. This is exactly the design concept that NVIDIA relied on on the high-end core. GF100/GF110 are all based on TLP to achieve high-efficiency scalar architecture.
In the end, AMD realized that the VLIW5 architecture is no longer suitable for continued development. It must prepare for the future a new high-efficiency architecture that not only increases the average utilization rate (greater than 3.4), but also needs to adapt to the parallel computing load. The result is to turn to VLIW4.
The most special feature of VLIW4 compared to VLIW5 is the elimination of the fifth SP t unit, or Special Function Unit (SFU), which has the largest volume and can handle common integer/floating-point operations and override operations simultaneously. This means that each SPU can reduce the number of ordinary integer/floating-point operations that can be processed at one time from five to four, and it is also possible to combine the three SPs to handle a transcendental operation.
There are many benefits to this change. The most obvious aspect of parallel computing is that the area of ​​the kernel used for special units can be saved to accommodate more SIMD engines, such as 20 Cypress Radeon HD 5800s and 24 Cayman Radeon HD 6900s. The average shader area is the latter. Block efficiency is 10% higher. At the same time, the number of texture units, the number of threads that can be executed in parallel, and the number of 64-bit floating-point operations that can be executed per clock cycle have changed. In particular, the latter makes AMD GPU 64-bit double-precision computing capabilities A quarter of the 32-bit single-precision floating-point (usually one-fifth) - in fact the computing power of a single stream processor unit does not change, but the layout is redesigned to make each other work more efficiently Now.
While the SP is changing, the register file is not moved, so the pressure on each SPU's register is less, because only four SPs now compete for register space. Scheduling is also simpler because the SPs that need to be scheduled are fewer and identical to each other, and there is no need to consider the difference between w/x/y/z cells and t cells.
Improvements in the game are similar. Games that are already accustomed to the VLIW5 architecture can be used with more SIMD engines, which means that the texture processing power is stronger, and the ratio of calculations/textures is reduced, which is good for games that focus on texture and filtering rather than computation.
Of course, any architectural changes will be sacrificed, and VLIW4 is no exception. For games, the Radeon HD 6900 will no longer handle VLIW5 vertex shaders as well as before. In general, this kind of game is already very fast, but if limited by the ability of GPU in the beginning (namely the video card is the bottleneck), Radeon HD 6900 series will not run fast. Another big loss is that Radeon HD 6800 can process two clocks per clock cycle when it comes to pairing the overrunning and vector operations. The Radeon HD 6900 requires two clock cycles. AMD thinks this situation is rare and the loss is worth it.
It is worth mentioning that AMD still considers VLIW4 to be a risky experimental design, and the Radeon HD 6900 is more like a pilot product. At this moment, AMD should have already completed a real trial and is designing a new core with a follow-up to the 28nm process. Whether or not VLIW4 continues to be adopted is certainly definitive.
Finally, the changes in the core architecture will inevitably involve the transformation and cooperation of drivers. The bad news is that many shader compilers designed for the VLIW5 architecture are useless, so the early stage shader compiler performance will be worse. The good news is that, over time, AMD will gradually master programming better for VLIW4, and the Radeon HD 6900 series also hopes to gain significant performance gains in the days to come (note that this is only possible).
With the shortening of VLIW, some code rewriting is inevitable. AMD's shader compiler will also go through a code optimization process. However, if the kernel itself is designed specifically for VLIW5, AMD's compiler is powerless.
Follow the comparison of the two architecture executable operations:
VLIW5:
4 32-bit FP MAD
Or 2 64-bit FP MUL/ADD
Or 1 64-bit FP MAD
Or 4 24-bit Int MUL/ADD
Plus 1 transcendental or 1 32-bit FP MAD
VLIW4:
4 32-bit FP MAD/MUL/ADD
Or 2 64-bit FP ADD
Or 1 64-bit FP MAD/FMA/MUL
Or 4 24-bit INT MAD/MUL/ADD
Or 4 32-bit INT ADD/Bitwise
Or 1 32-bit MAD/MUL
Or 1 64-bit ADD
Or 1 transcendental plus 1 32-bit FP MAD