Most of the technical breakthroughs come from actual product needs, and big data was originally born in Google's search engine. With the development of the web2.0 era, the amount of data on the Internet has exploded, and in order to meet the needs of information search, there is a very strong need for large-scale data storage. Based on cost considerations, it is becoming more and more impractical to solve the problem of large-volume data search by upgrading hardware. So Google proposed a software-based reliable file storage system GFS, which uses ordinary PCs to support large-scale storage in parallel. The data stored in it is of low value. Only when the data is processed can it meet the actual application needs. So Google has created the computational model of MapReduce, which can use the power of the cluster to split the complex operations into each one. On a normal PC, the final calculation result is obtained by summing up after the calculation is completed, so that it is possible to obtain better computing power by directly increasing the number of machines.
With GFS and MapReduce, the storage and operation of the files were solved, and new problems emerged. GFS's random literacy is very poor, and Google needs a database to store formatted data. The problem that could be solved by a single-machine database is tragedy at Google, so Google has developed a set of artifacts. The BigTable system, using GFS's file storage system plus a distributed lock management system Chubby, designed a columnar database system like BigTable.
After Google completed the above system, it released its thoughts as a paper. Based on these papers, there appeared a Hadoop-like open source project written in JAVA. The sponsor of Hadoop was yahoo. Later, this project became Apche's top project.
Big data solution:Google's system is closed source, and the open source Hadoop has spread widely.
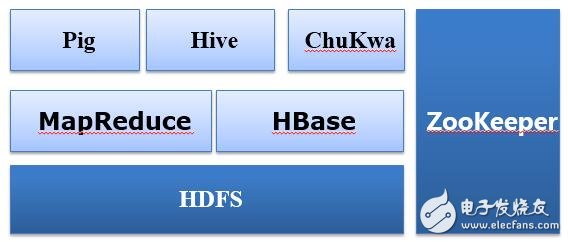
Similar to Google's system, Hadoop's core storage layer is called HDFS. The full name is Hadoop file storage system. With the storage system and analysis system, there is an open source version of MapReduce. A similar reference to BigTable is available. Hbase. After the open source, the whole system used more people, so everyone likes to have various features. Those of facebook think that the mapreduce program is too difficult to write, so Hive is developed. Hive is a tool that can convert SQL statements into Mapreduce. With this set of tools, you can use SQL to write mapreduce programs to analyze data. It is. By the way, referring to chubby, we have the open source ZooKeeper as a provider of distributed lock services.
Since Hadoop was originally designed to run files, it is no problem for batch processing of data. One day, suddenly everyone wants a real-time query service. The data is so large. To satisfy the real-time query, the first thing to throw away is mapreduce. Because it is really slow. In 2008, a company called Cloudera appeared. Their goal was to do redhat in the hadoop world, package various peripheral systems into a complete ecosystem, and later they developed impala, which is faster than mapreduce. The efficiency of real-time analytics has improved dozens of times, and then Hadoop founder Doug CutTIng joined cloudera. At this time, the academic school also began to exert strength. The University of California at Berkeley developed Spark to do real-time query processing. The syntax of Spark was very different at first, and then the Shark project gradually appeared, which gradually made Spark approach SQL syntax.
Future trends:The development of the era has determined that the future will almost become the era of data. In such an era, the demand for big data is getting deeper and deeper. Abandoning the past sample surveys and changing to full statistical analysis, from some original meaningless Mining value in the data. Big data has begun to gradually serve our lives, search, science, and user analysis. . .
In order to further provide the analysis ability of big data, the concept of memory computing will continue for a long time in the future. Through memory calculation, the ceiling effect of disk IO on performance will be abandoned, and the results of the operation will be presented to us in real time.
The amount of big data is huge and the format is diverse. Large amounts of data are generated by home, manufacturing plant and office equipment, Internet transaction transactions, social network activities, automated sensors, mobile devices, and scientific instruments. Its explosive growth has exceeded the processing power of traditional IT infrastructure, bringing severe data management problems to enterprises and society. Therefore, it is necessary to develop a new data architecture and develop and use the data around the whole process of “data collection, data management, data analysis, knowledge formation, and smart action†to release the hidden value of more data.
This DC Source System output current is up to 324A max by connecting the internal single unit rack mount DC Power Supply in parallel. Output voltage is up to 750VDC max (recommend not to exceed 800V) by connecting the internal single unit in series.
Some features of these adjustable dc power supply as below:
- With accurate voltage and current measurement capability.
- Coded Knob, multifunctional keyboard.
- Standard RS232/RS485/USB/LAN communication interfaces, GPIB is optional.
- Remote sensing line voltage drop compensation.
- Equips with LIST waveform editing function.
- Use the Standard Commands for Programmable Instrumentation(SCPI) communication protocol.
- Have obtained CE certification.
75V DC Source System,AC DC Electronics Power Supply,Dc Power System,Stable Dc Voltage Source
APM Technologies Ltd , https://www.apmpowersupply.com